网络字节序及其注意事项
网页上有许多关于字节序的讨论,这里就不多说了,只强调笔者认为最重要的两点:
- 字节序与 CPU 相关,或者说与计算机体系架构相关,而与操作系统无关。
- 字节序只针对多字节数据(如 int )才有意义,单字节数据(如 char)不用考虑字节序的问题。
笔者是这样理解上面两点的:
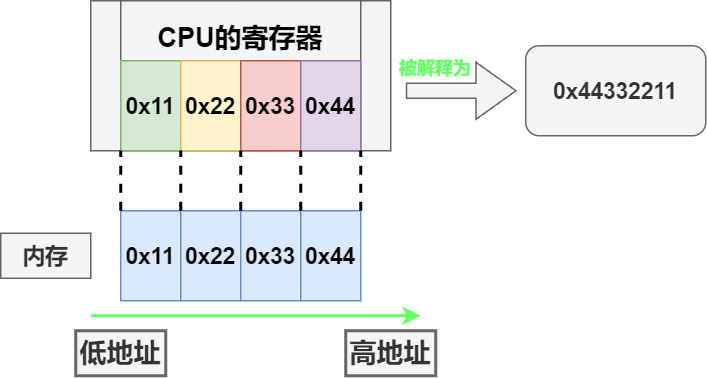
字节序就是指 CPU 中的寄存器对数据的解释方式 。32 位 CPU ,其寄存器大小为 4 字节,如果被设计为小端序,那么低地址的字节会被解释为低位数据,高地址的字节会被解释为高位数据:
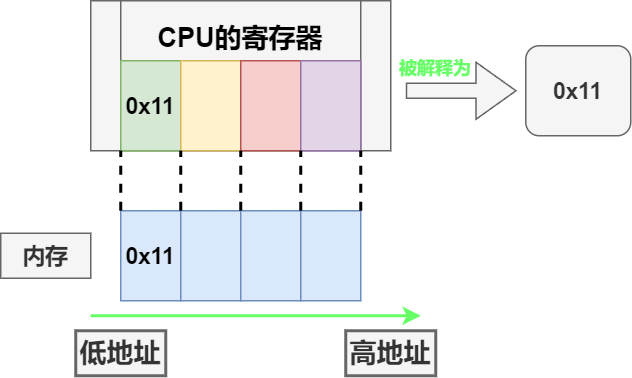
从上图也能看出,当单字节数据不会被解释方式(大小端)影响,比如 0x11 仍然被解释为 0x11:
那么,如何知道自己主机的大小端呢?很简单:
1 | int main() { |
如果输出 0x44,那么就是小端。有种常见的错误做法如下:
1 | int main() |
这段程序不论大小端,都会输出 0x34,因为数据截断时,总会保留最低有效字节,而不是保留地址处于最低位的字节 。最低有效字节中的“最低”是指的数据的低位,而不是内存地址的低位,比如 4 字节整型 0x11223344 截断为 1 字节的 char 时,就只会保留最低有效字节 0x44。截断的行为不会被大小端影响 。
下面来讨论网络字节序。
为了保证在不同字节序机器之间传输网络数据时数据能够被正确解释,规定网络数据传输的格式一律为大端序 。使用以下函数转换字节序:
1 | uint32_t ntohl (uint32_t netlong) |
SOCKET 网络编程初学者可能会疑惑,除了为端口和 IP 地址赋值时会用到上面的函数,其他时候我们发送网络数据都没有用到这些函数呀!这是因为大多数情况下我们都是发送的字符串数据,而字符都是 char,即单字节数据,因此根本不会被字节序影响 。那么我们来传输一个 int 整型试试:
1 | //client |
本机是小端序,使用 wireshark 抓取网络报文,可见数据仍是以小端序传输的。如果对端机器是大端序,那么字节序列 78 56 34 12 则会被解释为 0x78563412 ,从而造成数据错乱。

所以我们必须先将整型转为大端序:
1 | //.... |

从上面我们能得到:跨网络传输字符串或其他单字节数据时,不会受大小端影响;而传输多字节的二进制数据时,如果不提前转为大端序,那么就会发生错误。即使手动将二进制数据(如结构体)转为大端序,也存在以下几个问题:
- 两端机器对 C 数据类型的实现不同,比如本端机器的 int 为 4 字节,而对端的机器可能为 2 字节。
- 不同实现的结构体对齐方式存在差异。
可以使用以下两种方法解决以上问题:
- 将所有数值类型作为字符串来传递,显然效率很低。
- 自己定义一个二进制数据结构(协议)。
最后补充一点,大小端问题不仅出现在主机之间,在同一主机的不同进程之间也可能出现,比如在Java虚拟机中采用的是网络字节序(即大端字节序),因此在与其他进程进行数据交换时,需要进行字节序转换。








