前置内容:线程-基础-加载线程 thread-schedule
概览
任务链表 任务调度基础 thread.c 和 thread.h 进行改进。任务切换
任务调度基础 thread.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct task_struct { uint32_t * self_kstack; enum task_status status ; char name[16 ]; uint8_t priority; uint8_t ticks; uint32_t elapsed_ticks; struct list_elem general_tag ; struct list_elem all_list_tag ; uint32_t * pgdir; uint32_t stack_magic; };
thread.h 中只对 task_struct 添加了一些成员:
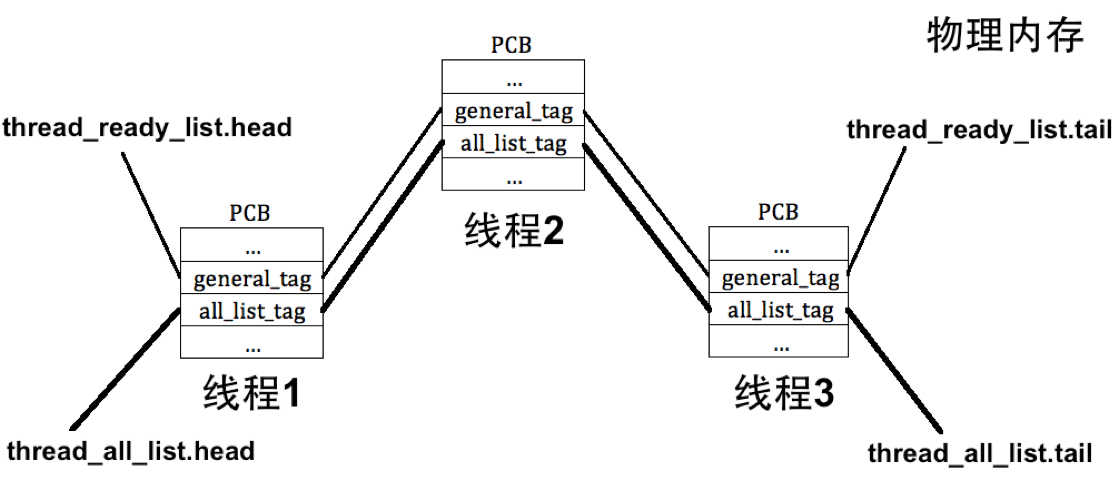
ticks: 时间片,任务刚被调度时,时间片被初始化为 priority,随后每发生一次时钟中断 ticks 就减 1,减到 0 后被换下 CPU 。elapsed_ticks: 记录该任务一共被运行了多少 CPU 滴答数。它和 ticks 的区别是:ticks 减到 0 时任务被换下 CPU,但此时任务可能还未执行完毕,所以重新加入到任务队列等待下一次被调度。所以,elapsed_ticks 记录的是从任务初次被调度到任务执行结束所经过的总滴答数,而 ticks 只是任务的一次倒计时。general_tag: 当任务处于就绪或其他等待状态 时,需要把该 tag 添加到 thread_ready_list 或其他相应等待队列中 。将 tag 加入到队列就相当于将 task_struct 加入到队列吗?是的,可以通过 tag 来定位 task_struct,原因很简单,因为这些 tag 本来就位于 task_struct 内存中,只需要根据成员的偏移量就能反向推断出 task_struct 的地址。文末会演示这一过程。all_list_tag: thread_all_list 用来管理所有任务,所有任务的 all_list_tag 都需要加入到 thread_all_list 中。pgdir: 上节提到过,对于进程,pgdir 指向自己的页目录表;对于线程,pgdir 被初始化为 NULL 。注意,pgdir 中装的是虚拟地址,经过手动转换变成物理地址后才会加载进 CR2 ,这是后话。
thread.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 #define PG_SIZE 4096 struct task_struct * main_thread ;struct list thread_ready_list ;struct list thread_all_list ;static struct list_elem * thread_tag ;static uint32_t tmp_esp;struct task_struct* running_thread () { asm volatile ("mov tmp_esp,esp" ) ; return (struct task_struct*)(tmp_esp & 0xfffff000 ); } static void kernel_thread (thread_func* function, void * func_arg) { intr_enable(); function(func_arg); } void thread_create (struct task_struct* pthread, thread_func function, void * func_arg) { pthread->self_kstack -= sizeof (struct intr_stack); pthread->self_kstack -= sizeof (struct thread_stack); struct thread_stack * kthread_stack =struct thread_stack*)pthread->self_kstack; kthread_stack->eip = kernel_thread; kthread_stack->function = function; kthread_stack->func_arg = func_arg; kthread_stack->ebp = kthread_stack->ebx = kthread_stack->esi = kthread_stack->edi = 0 ; } void init_thread (struct task_struct* pthread, char * name, int prio) { memset (pthread, 0 , sizeof (*pthread)); strcpy (pthread->name, name); if (pthread == main_thread) pthread->status = TASK_RUNNING; else pthread->status = TASK_READY; pthread->self_kstack = (uint32_t *)((uint32_t )pthread + PG_SIZE); pthread->priority = prio; pthread->ticks = prio; pthread->elapsed_ticks = 0 ; pthread->pgdir = NULL ; pthread->stack_magic = 0x19870916 ; } struct task_struct* thread_start (char * name, int prio, thread_func function, void * func_arg) { struct task_struct * thread =1 ); init_thread(thread, name, prio); thread_create(thread, function, func_arg); assert(!elem_find(&thread_ready_list, &thread->general_tag)); list_append(&thread_ready_list, &thread->general_tag); assert(!elem_find(&thread_all_list, &thread->all_list_tag)); list_append(&thread_all_list, &thread->all_list_tag); return thread; } static void make_main_thread () { main_thread = running_thread(); init_thread(main_thread, "main" , 31 ); assert(!elem_find(&thread_all_list, &main_thread->all_list_tag)); list_append(&thread_all_list, &main_thread->all_list_tag); } void schedule () { assert(intr_get_status() == INTR_OFF); struct task_struct * cur = if (cur->status == TASK_RUNNING) { assert(!elem_find(&thread_ready_list, &cur->general_tag)); list_append(&thread_ready_list, &cur->general_tag); cur->ticks = cur->priority; cur->status = TASK_READY; } else { } assert(!list_empty(&thread_ready_list)); thread_tag = NULL ; thread_tag = list_pop(&thread_ready_list); struct task_struct * next =struct task_struct, general_tag, thread_tag); next->status = TASK_RUNNING; switch_to(cur, next); } void thread_init (void ) { put_str("thread_init start\n" ,DEFUALT); list_init(&thread_ready_list); list_init(&thread_all_list); make_main_thread(); put_str("thread_init done\n" ,DEFUALT); }
老规矩,讲解以上代码前先理理脉络:
开启线程机制前需要调用 thread_init() 来初始化线程环境,内容包括初始化就绪任务链表和所有任务链表、创建 main 线程。 初始化线程环境后即可调用 thread_start() 创建线程。在此函数中进入如下动作: 1)调用 init_thread() 初始化线程信息, 2)调用 thread_create() 将线程函数及其参数写入到线程栈中。 3)将该线程加入到 thread_ready_list 和 thread_all_list 中。 随后等待调度。
下面进行代码讲解:
第 12 行,使用内联汇编取得当前 esp 的值。和之前一样,内联汇编中用到的 C 变量必须是全局或者全局静态变量,因此使用全局静态变量 tmp_esp 中转。
第 14 行,因为栈位于 PCB 中,而 PCB 大小为一页,所以将 esp 向下取页框,即得 PCB 起始地址。
第 21 行,进入线程函数 function() 前需要先打开中断,这里需要重点说明其原因:任务切换是由时钟中断驱动的,也就是说,schedule() 是在时钟中断里被调用的,任务调度后直接进入 function() 执行任务 ,并不会返回中断(iret) IF 位自动置 0,也就是屏蔽外部中断,如此一来,进入该任务后就无法发生时钟中断来调度其他任务啦,于是,该任务独占了 CPU 控制权!为了防止这种情况发生,我们需要在进入任务前手动开启中断
第 68 行,只有将该任务加入到 thread_ready_list 队列中,才会被 CPU 调度 ;目前还没有体现到 thread_all_list 的作用,后续才会用到该队列。
第 77 行,从 CPU 被启动的那一刻,执行流就一直在按我们的代码运行。现在,我们要将该执行流也包装成线程(即kernel_main线程)并加入到队列中,否则调度其他任务后就没法回到主线程了 。注意 guide.s :
1 2 3 4 5 6 7 [BITS 32] extern kernel_main global _start section .text _start: mov esp, 0xc009f000 jmp kernel_main
第 6 行,进入内核前必须将 esp 指向主线程 PCB 的顶端,即 0xc009f00 处,否则无法根据 esp 定位到 PCB 。
第 92 行,schedule() 函数可能在时钟中断里被调用,也可能被后续将要说到的 thread_block() 函数调用。因此,在 schedule() 中需要考虑当前线程是出于什么原因才被换下 CPU 的,是因为时间片到期?还是说被阻塞了?所以必须针对不同的状态做出相应的应对措施 switch_to 是汇编函数,下文会重点讲解。
第 109 行,由于我们还未实现 idle 线程,所以就绪队列可能为空,为了避免无线程可调度的情况,暂用 assert 来保障。
第 114 行,elem2entry() 是宏函数,用来将 general_tag 或 all_list_tag 转换为对应的 task_strcut 指针。此函数在文末介绍链表时会谈到。
其他就没什么好说的了,下面进入正题。
任务切换 我们采用的调度方式是 轮询(Round-Robin,RR)
完整的任务调度分为三个大步:
进入时钟中断 时钟中断调用 schedule() schedule() 调用 switch_to()
1.进入时钟中断 加入中断 一文中,我们将每个中断处理函数都统一初始化为 general_intr_handler() ,这是一般化函数,只是用来告诉我们发生了什么中断,以便于排错。现在咋们就需要将时钟中断专门化了,见以下代码:
1 2 3 4 5 6 void register_handler (uint8_t vector_no, intr_handler function) { interrupt_handler_table[vector_no] = function; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 uint32_t ticks; static void intr_timer_handler (void ) { struct task_struct * cur_thread = assert(cur_thread->stack_magic == 0x19870916 ); cur_thread->elapsed_ticks++; ticks++; if (cur_thread->ticks == 0 ) schedule(); else cur_thread->ticks--; } void timer_init () { put_str("timer_init start...\n" ,DEFUALT); frequency_set(CONTRER0_PORT, COUNTER0_NO, READ_WRITE_LATCH, COUNTER_MODE, COUNTER0_VALUE); register_handler(0x20 , intr_timer_handler); put_str("timer_init done: Clock interrupt frequency increased to 100Hz\n" ,DEFUALT); }
全局变量 ticks 用来记录自中断开启后经历的总滴答数,类似于系统运行时长的概念。该变量当前保留,未来可能会用到。
第 14 行,cur_thread->ticks == 0 意味着该任务还未结束,但时间片已经到期 ,所以进入 schedule() ,将该任务重新放入队尾等待下一次调度。
第 25 行,注册专门的时钟中断。
进入schedule()
上文已作讲解,不再说明。
进入switch_to
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 [bits 32] section .text global switch_to switch_to: ;栈中此处是返回地址 push esi push edi push ebx push ebp mov eax, [esp + 20] ; 得到栈中的参数cur, cur = [esp+20] mov [eax], esp ; 保存栈顶指针esp ;------------------ 以上是保存当前线程的栈,下面是恢复下一个线程的栈 ---------------- mov eax, [esp + 24] ; 得到栈中的参数next, next = [esp+24] mov esp, [eax] ; 恢复esp pop ebp pop ebx pop edi pop esi ret ;第一次执行时会返回到kernel_thread ;后续执行则会返回到schedule函数
关于 esi、edi、ebx、ebp 的压栈问题已在线程-基础-加载线程 中阐述。
参数 cur 和 next 分别是当前任务和下个任务的 task_struct 指针,需要强调的是,由于 task_struct 的首个成员是 self_kstack,所以可以认为 cur 和 next 指针也是指向 self_kstack !这样一来,self_kstack 的真正作用便清晰了——记录线程被换下瞬间的 esp 值
switch_to 是任务调度的核心,它向我们直接展示了操作系统是如何通过栈切换来完成任务调度的
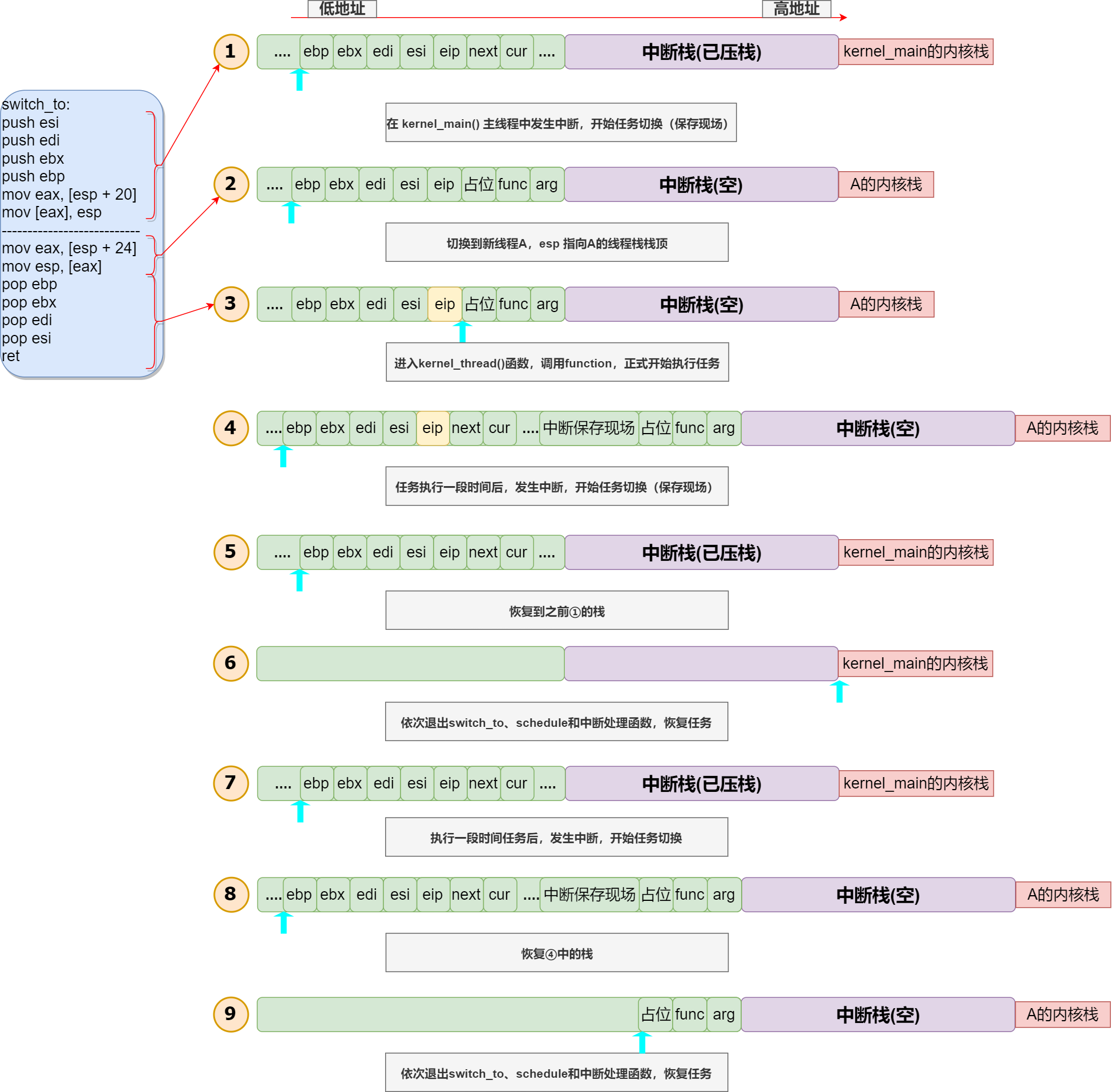
当前执行流位于 kernel_main() 主线程,esp 当然也位于 kernel_main 的 PCB 顶端。某一时刻,时钟中断发生,中断压栈保护任务现场 ,接着进入 schedule() ,进而到 switch_to() 。switch_to() 前半段将当前 esp 的值保存到 kernel_main 的 self_kstack 中。
为什么 cur 和 中断栈之间还有个省略号?这只是想告诉大家,实际的线程栈情况和 thread_stack 结构体并不能一一对应,比如,调用 schedule() 函数还需要将返回地址压栈呢,而这个并没有考虑进 thread_stack 或 intr_stack ,所以栈中的数据实际上是错位的!不能通过该结构体取得栈内对应的值。intr_stack 也同样不能对应,比如,在 kernel_main() 中调用了一个函数,执行此函数时发生中断,此时的 esp 就不是从 0xc009f000 开始的啦!
执行 mov esp,[eax] 后即完成栈切换。注意,这个新任务是首次被调度的,它的线程栈已经在 thread_create() 中被我们设计好了
为啥没省略号了?因为现在对齐啦!!!要知道,在 thread_create() 中,我们跳过了中断栈和线程栈,将 self_kstack 不偏不倚地指向了线程栈的起点,所以这里是完全对齐了的,也是基于这一点,下面的 pop 和 ret 才能正确执行。
四次 pop 并 ret,成功进入 eip 对应的 kernel_thread() ,进而 function() ,任务开始执行。
某时刻,中断再次发生,中断压栈,再一路来到 switch_to() 上半部分,即保存当前栈。注意,由图可见,此时中断压栈是发生在线程栈中而非中断栈中!
注意步骤 3 和步骤 4 的栈中的 eip 差异,这点差异非常重要!步骤 3 中的 eip 是我们设计好的,指向 kernel_thread() ;而步骤 4 中的 eip 是 schedule() 中调用 switch_to() 时留下的返回地址,也就是说将来会通过这个 eip 回到 schedule() function() 前手动打开了中断,这并不是 iret 的功劳。
执行 switch_to() 的下半部分,mov esp,[eax] ,切换任务栈。
接着 pop 并 ret,依次退出 switch_to() 、schedule() 和中断函数,恢复 kernel_main() 的任务。
一段时间后,中断发生,保存当前栈。
恢复之前的栈。此时的 eip 是 schedule() 留下的返回地址(而非 kernel_thread 的地址)。
pop 并 ret,依次退出 switch_to() 、schedule() 和中断函数,恢复线程任务。
可见,该线程的线程栈栈底将一直存留这三个参数,这并不重要。问题是,当任务结束后,kernel_thread() 该如何返回呢?这个占位符原本应该是 switch_to 调用 kernel_thread() 留下的返回地址,但现在它仅是一个占位符,这意味着任务结束后 kernel_thread() 将无法正常返回! 在我们的操作系统中,线程返回不能通过普通 return 的方式进行 thread_exit() )来结束任务,这是后话,目前我们的策略是强制要求在任务末端放一个 while(1) ,以避免任务结束。关于这点的实验演示见以下视频。
为什么使用 ret 来调用 kernel_thread() ? switch_to 的最后一句 ret ,在线程首次被调度时,是进入 kernel_thread() ;后续被调度时,则是返回到主调函数 schedule() 中。所以此处的 ret 有双重作用!而你可以通过 ret 调用 kernel_thread,也可以使用 ret 来返回 schedule,但你可不能使用 call 来返回 schedule 吧?这也是为什么要使用 ret 而非 call 来调用 kernel_thread() 的原因!
可见,一旦任务退出,就引发缺页异常。不知道有没有眼尖的小伙伴看见 while 语句中,打印语句上下的 STI 和 CLI ?为什么要在 put_str() 的上下分别放置这两条语句呢?先让我们看看,如果去掉这两条语句会发生什么:
看见了吗?若去掉 STI 和 CLI ,则会发生 0xd 号异常。这涉及到锁相关的内容,将在下节内容详细介绍。
另外,说说笔者在这里遇见的一个大坑,看下面的 interrupt.s :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 %macro VECTOR 2 INTERRUPT_ENTRY_%1 : ;中断处理entry %2 push ds push es push fs push gs pushad mov al,0x20 ;中断结束命令EOI out 0xa0 ,al ;向从片发送 out 0x20 ,al ;向主片发送 push dword %1 call [interrupt_handler_table + %1 *4 ] add esp, 4 ;外平栈 popad pop gs pop fs pop es pop ds add esp,4 ;跨过error_code,以保持堆栈平衡 iret ;从中断返回,32 位下等同指令iretd
上面是修改后的 interrupt.s ,也就是现在的版本。而之前,笔者是像下面这样写的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 %macro VECTOR 2 INTERRUPT_ENTRY_%1 : ;中断处理entry %2 push ds push es push fs push gs pushad push dword %1 call [interrupt_handler_table + %1 *4 ] add esp, 4 ;外平栈 popad pop gs pop fs pop es pop ds mov al,0x20 ;中断结束命令EOI out 0xa0 ,al ;向从片发送 out 0x20 ,al ;向主片发送 add esp,4 ;跨过error_code,以保持堆栈平衡 iret ;从中断返回,32 位下等同指令iretd
嗯?只是处理 EOI 的代码改变了位置,有什么影响吗?影响可大了!前文已经强调,任务调度在时钟中断处理函数(第11行)中进行的,调度完成后直接开始执行任务,并不会返回到中断内并执行末尾的 iret 指令;而中断发生后 CPU 会自动将 IF 位置零来屏蔽外部中断,因此,为了防止任务独占 CPU,任务(即function())正式开始前还要手动开中断。问题来了,8259A 芯片发送中断信号后,必须要收到 CPU 发来的 EOI 结束命令后才会继续发送中断,否则即使你开了中断也没用!
链表 双向链表是用来维护任务队列的核心数据结构。数据结构不是本系列博客的重点,所以就不详细展开了,仅强调几个要点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #define offset(struct_type,member) (int)(&((struct_type*)0)->member) #define elem2entry(struct_type, struct_member_name, elem_ptr) \ (struct_type*)((int)elem_ptr - offset(struct_type, struct_member_name)) struct list_elem { struct list_elem * prev ; struct list_elem * next ; }; struct list { struct list_elem head ; struct list_elem tail ; }; typedef bool (function) (struct list_elem*, int ) ;void list_init (struct list *) ;void list_insert_before (struct list_elem* before, struct list_elem* elem) ;void list_push (struct list * plist, struct list_elem* elem) ;void list_iterate (struct list * plist) ;void list_append (struct list * plist, struct list_elem* elem) ;void list_remove (struct list_elem* pelem) ;struct list_elem* list_pop (struct list * plist) ;bool list_empty (struct list * plist) ;uint32_t list_len (struct list * plist) ;struct list_elem* list_traversal (struct list * plist, function func, int arg) ;bool elem_find (struct list * plist, struct list_elem* obj_elem) ;
offset 宏用来计算结构体内的某成员相对于该结构体起始处的偏移量。这个操作很骚,可以说将指针运用得炉火纯青了:
1 (int )(&((struct_type*)0 )->member)
将 0 强制转换为 struct_type* 指针,换句话说,该指针指向 struct_type 类型的结构体,而该结构体位于地址 0x0000 处
elem2entry 宏就好说了,用 tag 指针减去 tag 偏移量即得结构体的起始地址。
1 struct task_struct * next =struct task_struct, general_tag, thread_tag);
那么,为什么这两个操作设计成宏而非函数呢?留给读者自己思考。
注意,list 中的 head 是头节点,而非首元节点;尾节点同理;节点只会插在 head 与 tail 之间。
头节点是一个不存放任何数据的空节点,通常作为链表的第一个节点。对于链表来说,头节点不是必须的,它的作用只是为了方便解决某些实际问题 ;
第 19 行,自定义函数类型,该类型在 list_traversal() 中作为回调函数的类型。如果不使用 typedef,那么第 30 行声明就需改成:
1 struct list_elem* list_traversal (struct list * plist, bool (func)(struct list_elem*, int ), int arg) ;
显然,这种方式没有上一种方式好看。list_traversal() 函数当前还未使用,后续用到了再介绍。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 void list_init (struct list * list ) { list ->head.prev = NULL ; list ->head.next = &list ->tail; list ->tail.prev = &list ->head; list ->tail.next = NULL ; } void list_insert_before (struct list_elem* before, struct list_elem* elem) { enum intr_status old_status = before->prev->next = elem; elem->prev = before->prev; elem->next = before; before->prev = elem; intr_set_status(old_status); } void list_push (struct list * plist, struct list_elem* elem) { list_insert_before(plist->head.next, elem); } void list_append (struct list * plist, struct list_elem* elem) { list_insert_before(&plist->tail, elem); } void list_remove (struct list_elem* pelem) { enum intr_status old_status = pelem->prev->next = pelem->next; pelem->next->prev = pelem->prev; intr_set_status(old_status); } struct list_elem* list_pop (struct list * plist) { struct list_elem * elem = list_remove(elem); return elem; } bool elem_find (struct list * plist, struct list_elem* obj_elem) { struct list_elem * elem = while (elem != &plist->tail) { if (elem == obj_elem) return true ; elem = elem->next; } return false ; } struct list_elem* list_traversal (struct list * plist, function func, int arg) { struct list_elem * elem = if (list_empty(plist)) return NULL ; while (elem != &plist->tail) { if (func(elem, arg)) return elem; elem = elem->next; } return NULL ; } uint32_t list_len (struct list * plist) { struct list_elem * elem = uint32_t length = 0 ; while (elem != &plist->tail) { length++; elem = elem->next; } return length; } bool list_empty (struct list * plist) { return (plist->head.next == &plist->tail ? true : false ); }
上面的函数都是常规的链表操作,不再解释。
本文结束。经过这两节的煎熬,想必读者朋友们也憔悴了吧?哈哈,休息再战!