详解字符串操作函数
本节对应分支:
string
下节我们将要实现内存管理,这不可避免地要频繁使用到 memcpy、memset 等函数,有了内存操作函数就很容易实现字符串操作函数 strcpy、strcat 等。所以这节我们来实现内存操作和字符串操作函数。本节内容虽然简单,但有许多代码规范需要注意,还请读者不可掉以轻心。
memset
1 | void memset(void* dst, char var, unsigned int size) |
注意,void* 是无法直接作指针运算的,因为编译器无法确定其步长及其解释方式 。因此,需要定义 unsigned char* tmp 来代替 void* dst ,tmp 指针的步长即为 1 字节。以下同理。
什么是指针的步长?就是指
++或--时指针移动的字节数。
什么是解释方式?就是指定编译器如何去解释指针所指向的这个数据。
memcpy
1 | void memcpy(void* dst, void* src, unsigned int size) |
这个函数有以下两点需要注意:
- 规范问题:能直接
assert(dst!=NULL && src!=NULL)吗?
当然可以,但出问题时,你怎么确定是 dst 还是 src 的问题?所以最好细化,便于追踪错误。 - 解决了 内存重叠 的问题,参考memcpy和memmove 。
memcpy
1 | int memcmp(const void* mem1, const void* mem2, unsigned int size) |
strcpy
1 | char* strcpy(char* dst,const char* src) |
- 字符串 src 是不会被改变的,所以要声明为 const 。
- 注意第 5 行的检查,这是我们容易忽略的地方。
- 第 8 行,赋值运算符也是有返回值的,其返回所赋的值,即
*src。
上面代码看上去无懈可击,实际上也存在内存重叠的问题:
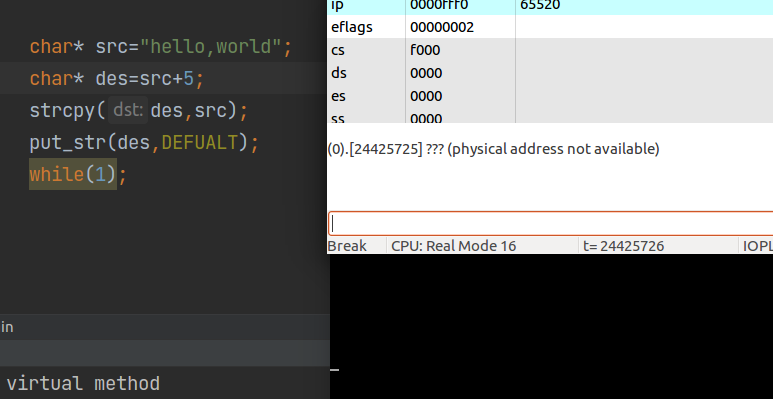
因此将代码改为如下:
1 | char* strcpy(char* dst, const char* src) |
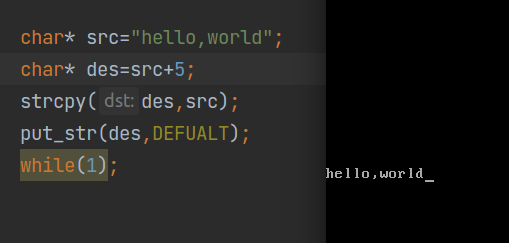
strlen
1 | unsigned int strlen(const char* str) |
最后的 -1 可别忘了。
这种方式很容易忽略 1,保险可采用此方式:
while(*tmp) tmp++;;如此就无需减 1 。
strcmp
1 | int strcmp(const char* dst, const char* src) |
注意第 10 行,把 0、1、-1三种情况都概括了,很漂亮的方式。
strchr与strrchr
strchr :参数 str 所指向的字符串中搜索第一次出现字符 c 的位置。
1 | char* strchr(const char * str,char ch) |
strrchr :参数 str 所指向的字符串中搜索最后一次出现字符 c 的位置。
1 | char* strrchr(const char* str,char ch) |
strcat
string-concatenate:
1 | char* strcat(char* dst, const char* src) |
strchrs
string-char-reserch:
1 | unsigned int strchrs(const char* src, char ch) |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 极简!
相关推荐





评论


