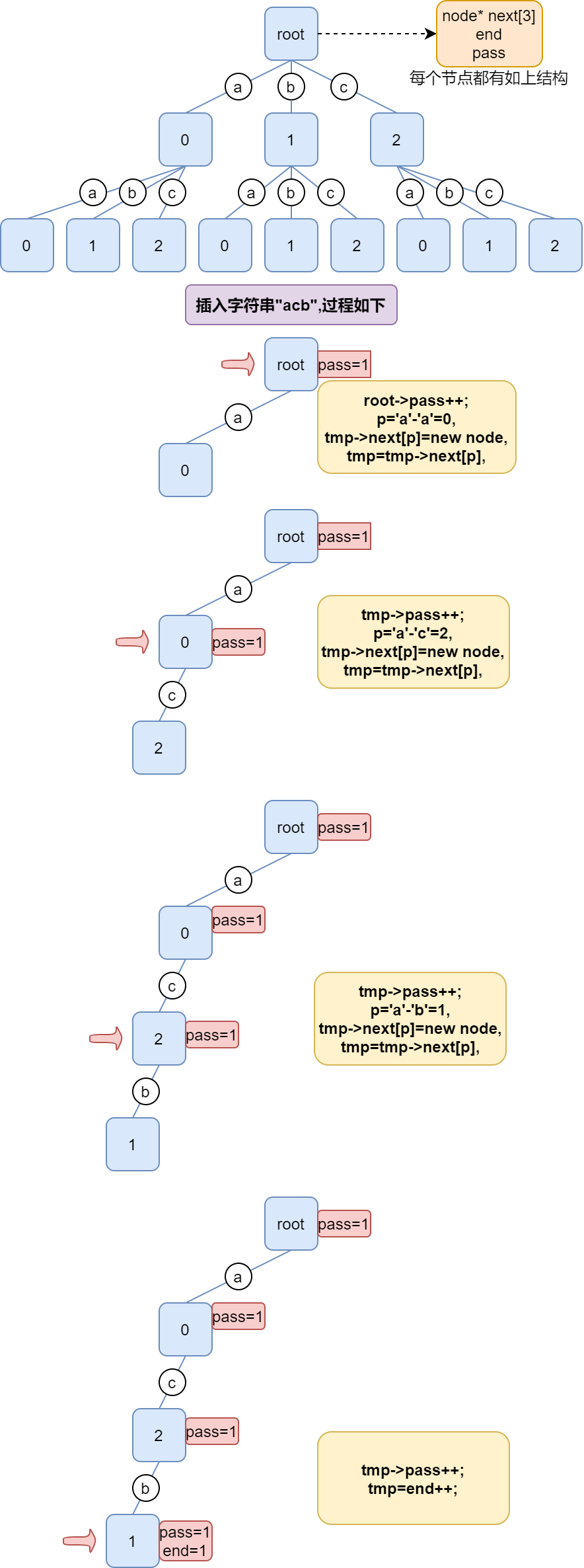
前缀树又叫字典树,通常用来高效地查询字符串,比如查询库中是否有以某个子字符串为前缀的字符串,某个字符串出现的次数等。前缀树是 N 叉树的一种特殊形式,每一个节点会有多个子节点,通往不同子节点的 路径上 有着不同的字符,子节点中包含两种信息:pass(经过此字符的次数),end(以此字符结尾的次数)。说多了没用,直接上图:
0-‘a’,1-’b’,2-‘c’,每个节点对应的下标即代表相应字母,除 root 外的其他节点中包含着该字母的信息。
细心的同学应该发现,root 的 end 域只可能为 0,因为这代表着插入了一个空字符串,这是不被允许的。所以我们似乎可以利用这个 end 域做些坏事。容易知道,root 的 pass 域代表着此前缀树中一共有多少个字符串(相同字符串会被重复计数),那么,我如果想知道一共有多少种字符串呢?此时,就要利用 root 的 end 域来记录了。详细注释已在代码给出,不在赘述。代码如下(仅支持小写字母):
#include<iostream> #include<string> using std::string; using std::cout; using std::endl; structnode { int pass; int end; node* nexts[26]; node():pass(0), end(0) { for(int i = 0; i < 26; i++) nexts[i] = NULL; } };