TCP重传机制详解
超时重传
超时重传基于定时器,以时间驱动重传 。当发送端发送数据包后会启动相应计时器,如果在一定时间内未收到接收端发来的 ACK 报文导致计时器超时,则会重传相应报文。
需要注意的是,是仅重发相应超时报文还是重发所有未完成(已发出但未收到 ACK)的报文,在各个机制中有所不同(这取决于定时器的数量)。比如在【停等协议】中, 仅有一个定时器,一旦超时,重发所有未完成包;而在【选择重传协议】中,每个报文都有一个定时器,超时后仅重传对应报文。详细内容见:详解ARQ协议
超时重传面临三个主要问题:
-
RTO(重传时间) 如何确定?
-
超时才发生重传,延迟较高。
-
发生超时后,重传哪些包?
比如,发送端按序发送 1,2,3,4,5 个包,发送端只接收到第 1,2,4,5个包,那么接收端只能发送 ACK = 3 的 ACK 报文(表明 3 之前的都已收到),发送端收到 ACK 报文后,定时器超时, 由于此时第 3,4,5 的 ACK 报文都没有收到,那么发送端该重发哪些报文呢?只发 3 的报文还是发送 3,4,5 的报文?前者会节省带宽,但是若 4,5 真的也丢失了,又会等待重传;后者会快一点,但是会浪费带宽,也可能会有无用功。
对于第一个问题,笔者写了另一篇文章详尽阐述,参见此处 ;对于第二个问题,快速重传 机制会很好地解决;对于第三个问题,SACK 机制派上用场。另外需要知道的是,若连续超时重传,则会进行 指数回退 ,超过一定次数则会终止连接,务必参见重传示例 。
快速重传
快速重传不以时间为驱动,而以数据驱动重传。 【快速重传】机制如下图:
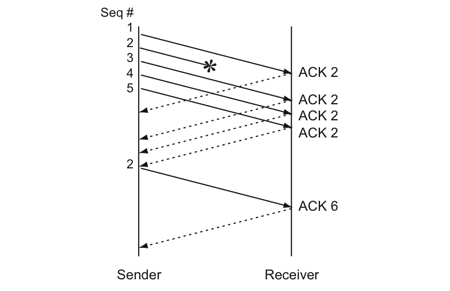
如果发送方发出了 1,2,3,4,5 份数据,第一份先到送了,于是就 ACK 回2,结果 2 因为某些原因没收到,3 到达了,于是还是 ACK 回2;后面的 4 和 5 都到了,但是还是 ACK 回 2,因为 2 还是没有收到,于是发送端收到了四个 ACK = 2 的确认,知道了 2还 没有到,于是就马上重传 2。然后,接收端收到了 2,此时因为 3,4,5 都收到了,于是回复 ACK = 6 。
注意!大多数书上和博客对【重复】描述并不清晰,个人认为应该如此描述:1. 收到三个 冗余 的ACK,重传;2. 收到四个 重复 的ACK,重传;
为什么要重复三次才发送?
那是因为 dup ACK 即可能是丢包造成的,也可能是网络乱序造成的。基于实验,定值为 3 ,参见 此处。
然而,【快速重传】机制只解决了【超时重传】的时间延迟较长的问题,但还是没有解决第三个问题。对于上面的示例来说,是重传 2 呢还是重传 2,3,4,5呢?因为发送端并不清楚这连续的 3 个 ACK = 2 是谁传回来的。也许发送端发了 20 份数据,是 6,10,20 传来的呢。这样,发送端很有可能要重传从2到20的这堆数据(这就是某些 TCP 的实际的实现)。为此,引入【SACK方法】。
SACK
【SACK】即 Selective Acknowledgment ,这种方式需要在 TCP 头部里加一个 SACK 选项,选项格式如下:
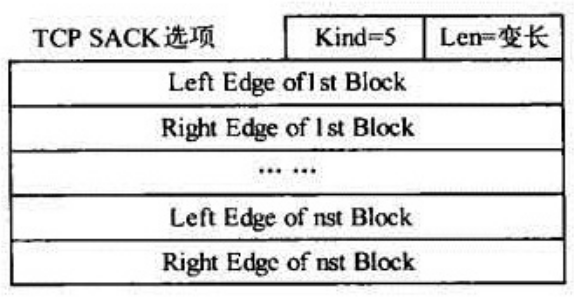
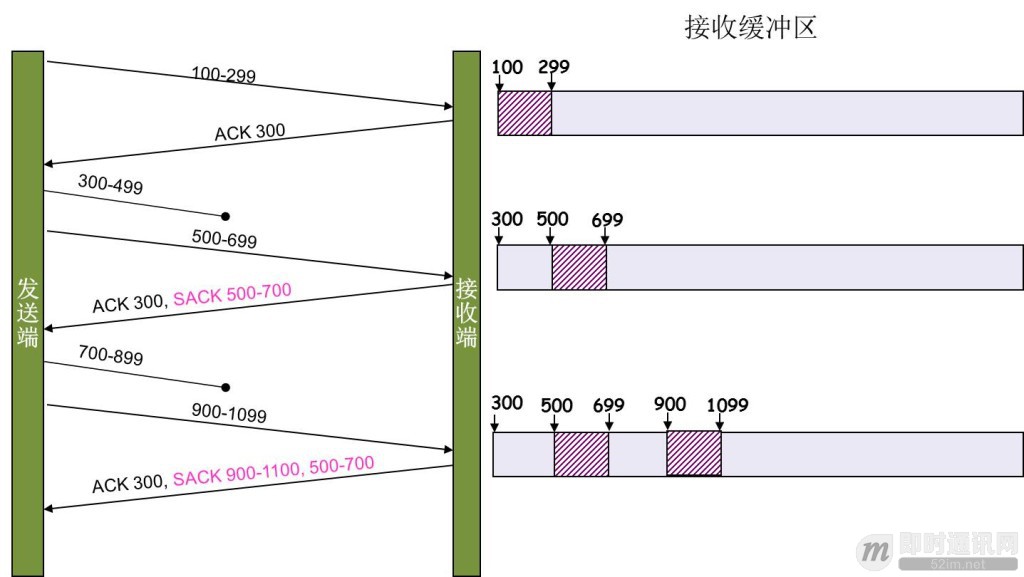
SACK 汇报的是接收方当前 ACK 号之后的已经收到的字节数。通过 SACK ,发送方就可以判断接收方还有哪些包没有收到,进而就可以只重传特定的分组,大大提高了效率。同时注意:
- 如果要支持
SACK,必须双方都要支持,在 Linux 下,可以通过net.ipv4.tcp_sack参数打开这个功能(Linux 2.4 后默认打开); - TCP的选项不能超过40个字节,所以 SACK 段不能超过4组。
- 接收方可能 Reneging,所谓 Reneging 的意思就是接收方有权把已经报给发送端 SACK 里的数据给丢了。这样干是不被鼓励的,因为这个事会把问题复杂化了,但是,接收方这么做可能会有些极端情况,比如要把内存给别的更重要的东西。所以,发送方也不能完全依赖 SACK ,还是要依赖 ACK,并维护 Time-Out,如果后续的 ACK 没有增长,那么还是要把 SACK 的东西重传。
- SACK 会消费发送方的资源,试想,如果一个攻击者给数据发送方发一堆 SACK 的选项,这会导致发送方开始要重传甚至遍历已经发出的数据,这会消耗很多发送端的资源。
需要注意,【SACK】是【选择性确认】,不同于 ARQ 协议中的【选择重传】,二者有相似之处,但前者并不代替 ACK,只是在 ACK 报文中添加额外的信息来帮助发送方进行确认。
DSACK
Duplicate SACK 又称 D-SACK,其主要使用了 SACK 来告诉发送方有哪些数据被重复接收了。采用如下方法判断是 SACK 还是 DSACK:
- 如果 SACK 的第一个段的范围被 ACK 所覆盖,那么就是 DSACK
- 如果 SACK 的第一个段的范围被 SACK 的第二个段覆盖,那么就是 DSACK
DSACK 用法举例:
1 | 一.ACK丢包 |
可见,引入了D-SACK,有这么几个好处:
- 可以让发送方知道,是发出去的包丢了,还是回来的 ACK 包丢了。
- 是不是自己的 timeout 太小了,导致重传。
- 网络上出现了先发的包后到的情况
- 网络上是不是把我的数据包给复制了。
知道这些东西可以很好得帮助 TCP 了解网络情况,从而可以更好的做网络上的流控。Linux下的 tcp_dsack 参数用于开启这个功能(Linux 2.4后默认打开)。
从纠错层面上而言,DSACK 和 SACK 完全相同,只是 DSACK 在收到包且重复的情况下也会反馈信息给发送方,使发送方更全面地了解网络情况。
早期重传(ER)
学习【快速重传】时,你可能会想到,万一经常出现发送方只收到两次或者一次冗余的 ACK 报文而无法快速重传报文时,咋办?只有等定时器超时吗?那这样效率是不是又会降下来?是对,为了解决此类情况,谷歌提出了【早期重传】。
按照 RFC5827,ER 有两种形式一种是基于字节的,一种是基于包的,基于包的ER精度要高于基于字节的ER,linux 实现的是基于 TCP 包的 ER,因此我们这里只介绍基于包的ER。
ER 是在没有新数据可以发送的场景下降低快速重传 dup ACK的门限 ,dup ACK 是由乱序 TCP 报文触发的,但是发出的总数据包的个数少于 4 个的时候,就会因为没有足够的 dup ACK 而不能触发快速重传(假设默认 dup ACK 门限是 3)。当同时出现下面两个条件时,启用ER:
- 发出去的但是还没有收到ACK确认的TCP报文个数 (oseg) 小于 4。
- 缓存中没有未发送数据或者发送窗口受限不能发送新数据 (如果允许发送新数据的话就可以进一步触发 dup ACK 来达到门限了。)
当满足上面两个条件时候,如果这个 TCP 未使能 SACK 的时候,用来触发 ER 的 dup ACK 门限必须降低为 ER_thresh = oseg - 1 ;当这个 TCP 连接 SACK 的时候,触发 ER 的条件则变为,(oseg-1) 个TCP包已经被 SACK 确认 。
最好启用 SACK ,原因如下:
假设发送 1,2,3 个包,第 1,3 个包顺利到达,第 2 个包丢失,此时可能有以下两种情况:
- 第 1 个包被接收到时延迟确认,当收到第 3 个包时,必须发送 ACK=2 包(延迟确认机制最多只能延迟一个包)。那么此时如果未开启 SACK ,发送发就会收到一个正常的 ACK,而不是 dup ACK 。这样一个 dup ACK 都没有收到过,所以也就不会触发ER机制,而只能靠RTO超时来进行重传(而且S2和S3都要重传);如果开启了 SACK,则发送方知道第 1,3 个包已经被收到,于是确认(SACKED)这两个包,并启用 ER 发送第 2 个包。
- 第 1 个包被收到时直接返回确认,则都会开启 ER 。
参考文章:重传次数到底怎么定? ,早期重传 ,TCP详解 ,TCP 20





